
MariaDB Galera Cluster部署实战
背景
项目中使用的mariadb+gelera集群模式部署,之前一直用的是mysql的master/slave方式部署数据库的,这种集群模式以前没怎么搞过,这里研究并记录一下。
MariaDB Galera Cluster 介绍
MariaDB 集群是 MariaDB 同步多主机集群。它仅支持 XtraDB/ InnoDB 存储引擎(虽然有对 MyISAM 实验支持 - 看 wsrep_replicate_myisam 系统变量)。
主要功能:
同步复制
真正的 multi-master,即所有节点可以同时读写数据库
自动的节点成员控制,失效节点自动被清除
新节点加入数据自动复制
真正的并行复制,行级
用户可以直接连接集群,使用感受上与MySQL完全一致
优势:
因为是多主,所以不存在Slavelag(延迟)
不存在丢失事务的情况
同时具有读和写的扩展能力
更小的客户端延迟
节点间数据是同步的,而 Master/Slave 模式是异步的,不同 slave 上的 binlog 可能是不同的
技术:
Galera 集群的复制功能基于 Galeralibrary 实现,为了让 MySQL 与 Galera library 通讯,特别针对 MySQL 开发了 wsrep API。
Galera 插件保证集群同步数据,保持数据的一致性,靠的就是可认证的复制,工作原理如下图:
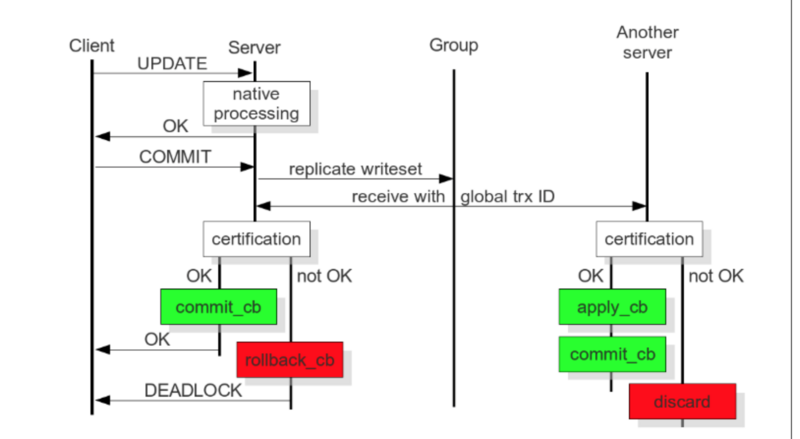
当客户端发出一个 commit 的指令,在事务被提交之前,所有对数据库的更改都会被write-set收集起来,并且将 write-set 纪录的内容发送给其他节点。
write-set 将在每个节点进行认证测试,测试结果决定着节点是否应用write-set更改数据。
如果认证测试失败,节点将丢弃 write-set ;如果认证测试成功,则事务提交。
MariaDB Galera Cluster搭建
我这里实验时使用的操作系统是CentOS7,使用了3台虚拟机,IP分别为10.211.55.6、10.211.55.7、10.211.55.8
关闭防火墙及selinux
为了先把MariaDB Galera Cluster部署起来,不受防火墙、selinux的干扰,先把3台虚拟机上这俩关闭了。如果防火墙一定要打开,可参考这里设置防火墙规则。
添加mariadb的yum源
在3台虚拟机上执行以下命令
安装软件包
在3台虚拟机上执行以下命令
数据库初始化
在10.211.55.6上执行以下命令
修改galera相关配置
在3台虚拟机上均打开/etc/my.cnf.d/server.cnf进行编辑,修改片断如下:
启动MariaDB Galera Cluster服务
先在第1台虚拟机执行以下命令:
出现 ready for connections ,证明启动成功,继续在另外两个虚拟机里执行命令:
等后面两个虚拟机里mariadb服务启动后,再到第1台虚拟机里执行以下命令:
验证MariaDB Galera Cluster服务
在任意虚拟机里执行以下命令:
查看集群全部相关状态参数可执行以下命令:
至此,MariaDB Galera Cluster已经成功部署。
MariaDB Galera Cluster的自启动
在实际使用中发现一个问题,Galera集群启动时必须按照一个特定的规则启动,研究了下,发现规则如下:
如果集群从来没有启动过(3个节点上都没有
/var/lib/mysql/grastate.dat文件),则必要由其中一个节点以--wsrep-new-cluster参数启动,另外两个节点正常启动即可如果集群以前启动过,则参考
/var/lib/mysql/grastate.dat,找到safe_to_bootstrap为1的节点,在该节点上以--wsrep-new-cluster参数启动,另外两个节点正常启动即可如果集群以前启动过,但参考
/var/lib/mysql/grastate.dat,找不到safe_to_bootstrap为1的节点(一般是因为mariadb服务非正常停止造成),则在3个节点中随便找1个节点,将/var/lib/mysql/grastate.dat中的safe_to_bootstrap修改为1,再在该节点上以--wsrep-new-cluster参数启动,另外两个节点正常启动即可
从以上3种场景可知,正常情况下很难保证mariadb galera cluster可以无人值守地完成开机自启动。国外论坛上也有人反映了这个问题,但好像官方的人员好像说设计上就是这样,怎么可以这样。。。
最后写了个脚本,放在3个虚拟机上面,解决了这个问题。脚本如下:
然后3个节点终于可以开机自启动自动组成集群了。
搭配keepalived+haproxy+clustercheck
为了保证mariadb galera集群的高可用,可以使用haproxy进行请求负载均衡,同时为了实现haproxy的高可用,可使用keepalived实现haproxy的热备方案。keepalived实现haproxy的热备方案可参见之前的博文。这里重点说一下haproxy对mariadb galera集群的请求负载均衡。
这里使用了 https://github.com/olafz/percona-clustercheck 所述方案,使用外部脚本在应用层检查galera节点的状态。
首先在mariadb里进行授权:
下载检测脚本:
准备检测脚本用到的配置文件:
测试一下监控脚本:
使用xinetd暴露http接口,用于检测galera节点同步状态:
测试一下暴露出的http接口:
最后在/etc/haproxy/haproxy.cfg里配置负载均衡:
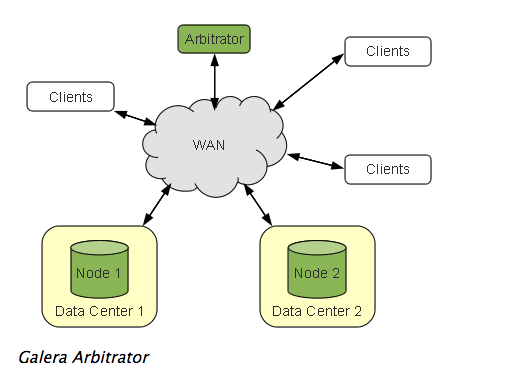
搭配galera仲裁服务
官方也提到gelera集群最少要三节点部署,但每增加一个节点,要付出相应的资源,因此也可以最少两节点部署,再加上一个galera仲裁服务。
The recommended deployment of Galera Cluster is that you use a minimum of three instances. Three nodes, three datacenters and so on.
In the event that the expense of adding resources, such as a third datacenter, is too costly, you can use Galera Arbitrator. Galera Arbitrator is a member of the cluster that participates in voting, but not in the actual replication
这种部署模式有两个好处:
使集群刚好是奇数节点,不易产生脑裂。
可能通过它得到一个一致的数据库状态快照,可以用来备份。
这种部署模式的架构图如下:
部署方法也比较简单:
测试一下效果。
首先看一下两节点部署产生脑裂的场景。
再试验下有仲裁节点参与的场景。
以前试验说明采用了仲裁节点后,因为集群节点数变为了奇数,有效地避免了脑裂,同时将真正有故障的节点隔离出去了。
参考
最后更新于